执行代码:rm ~/Library/Containers/com.haskellformac.Haskell.basic/Data/Library/Application\ Support/Haskell/.lHlchefrmhhasefcbl
就可以啦~
Linus的链表
Linus的链表
首先放链接: TED演讲—Linus
偶然看到了这个TED,看到Linus聚聚的神一般的链表删除操作,不用分情况讨论,简直是大开眼界……有感而发,写下一篇博文写下感受。最好还是先看下TED~听Linus聚聚谈人生是一种享受。
我们先假定我们的API设计是链表结构完全有序的插入。也就是,每次插入都插入在完全正确、使链表有序的位置上。如果我们调用insert(5)插入在[1, 2, 6, 7]的链表上,那么链表最终会变成[1, 2, 5, 6, 7]的状态。
按照我们正常的思维,链表应该是这样的:
(注:一个结点上一行是结点名称,下一行是类型名称。)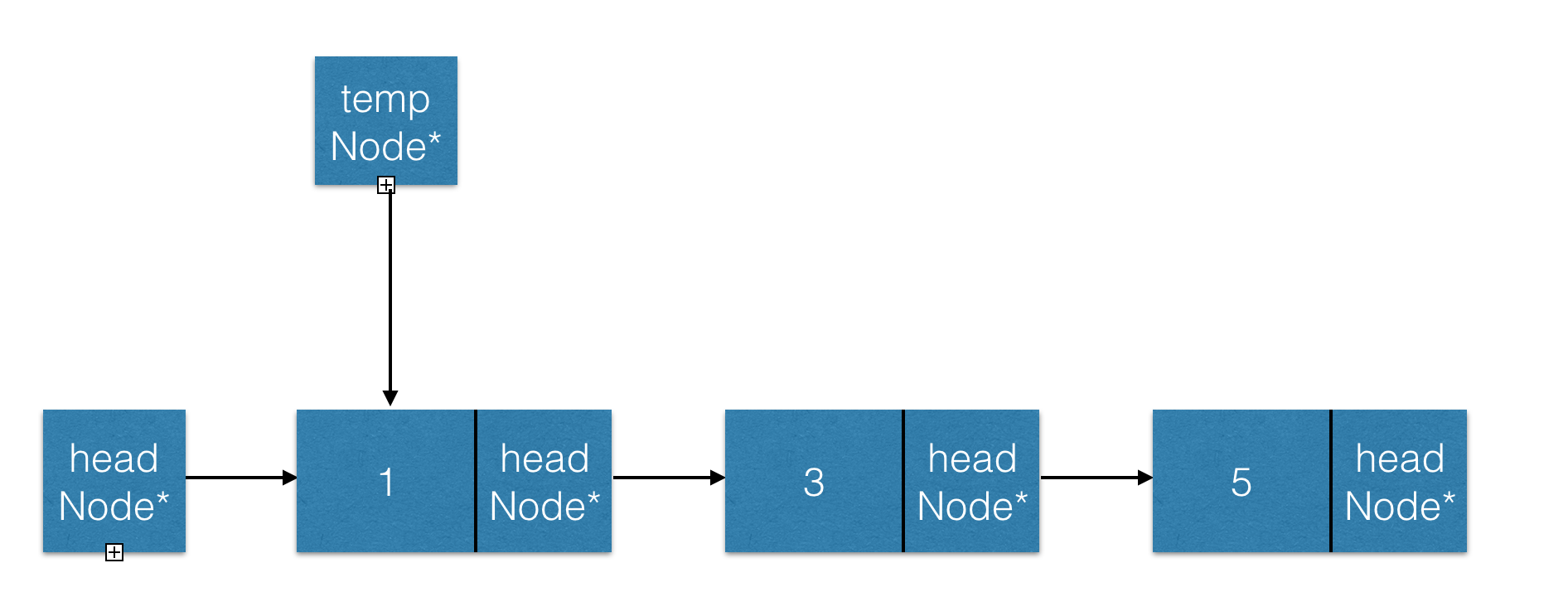

于是我们有了两种情况。但是实际上仔细一看,第二种NULL的情况是包含在第一种之中的。因为我们移动链表指针的时候,一定是做while(temp && temp->data < target_data)形式的循环体的。也就是:最终temp一定会停留在NULL或者≥target_data的第一个位置的。也就是,插入的正确位置。所以其实两种情况是一样的。因此我们只需要看第一种就好。于是就如下图: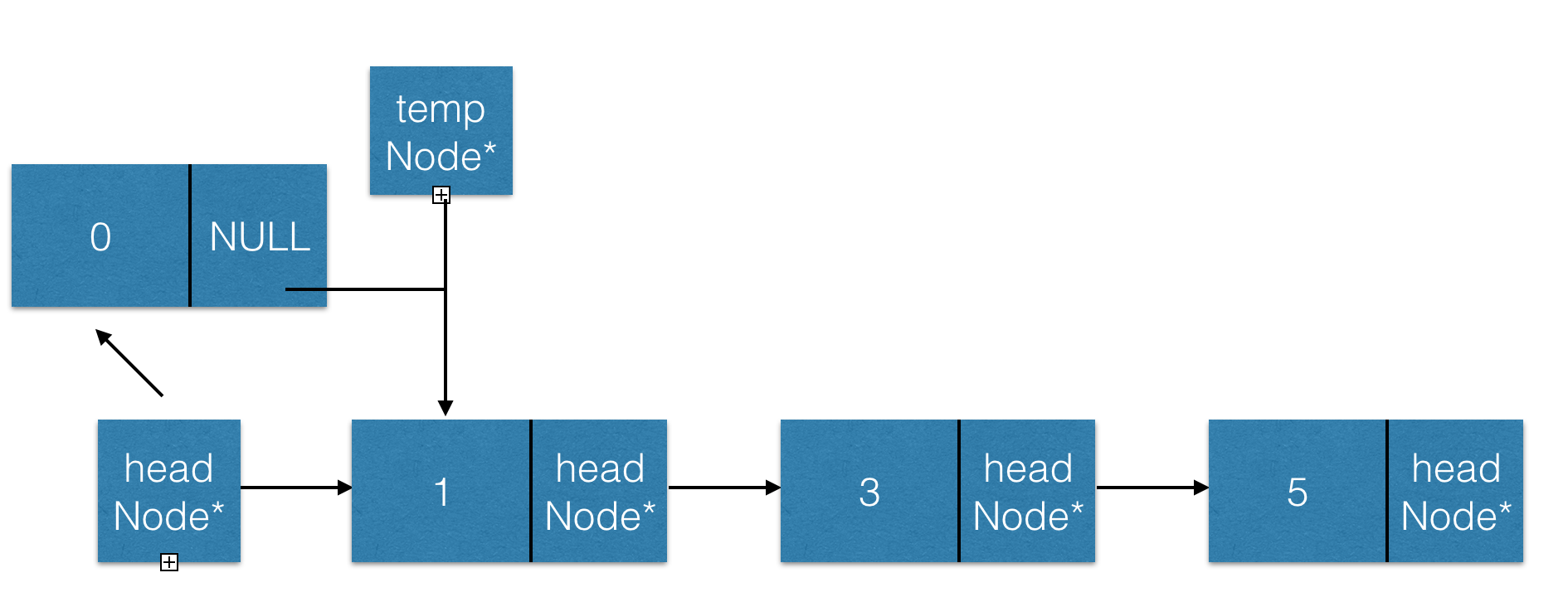
1.这里是我们在头结点插入的情况。非常简单啊。因为我们插入0,那么temp最终必然在1的位置上了。这样,我们只要利用head结点,就可以完成插入操作啦!
2.这里是我们在中间插入的情况。我们要插入4这个数。但是因为我们的temp正好就在需要插入的位置,也就是new Node的next有着落啦。但是我们的前一个结点必须重定位到新插入的new Node上去。可是我们并没有这种pre指针。也就是,仅仅使用一个指针,3这个点根本没法衔接到4的身上。好麻烦啊!于是解决办法就是,我们必须要使用一个pre和一个next指针来定位辅助操作,像这样:
卧槽。这简直神烦啊。光是插入操作就需要两种讨论=>头插和中间插。鉴于尾插和中间插是相同的(也就是next指针是NULL而已),可以省略尾插的讨论。那删除呢?删除也是一样的。头删除和中间删除。Linus在TED中说,头删除和中间删除是两种完全不同的情况。确实如此。。。(掀桌)
于是Linus大神给我们了另一种方法!!利用二级指针!
简洁起见,先上图讨论链表的改版:

(请注意指针指向的位置)
如图我们看到,不同于正常链表在于,这里创建了一个Node**类型的指针。这个指针有神马用处呢?特别神奇。因为它能够帮助我们使用类似“隔山打牛”的手段,远程地操纵链表结构,达到不必在插入和删除的时候需要分情况讨论的效果。
首先我们由图中可以看到。head结点一定是Node*类型的指针,不必多说。而我们在head的上边又创建了一个Node**的指针指向了head。和刚才正常思路的讨论不同的是,这里的temp是Node**类型了。当我们插入的时候,循环判断的条件变成了:while(*temp && (*temp)->data < target_data)了。其实和刚才的while(temp && data < target_data)是一样的。但是不同的是:这时的temp的位置,由正好指向“需要插入位置”的尴尬位置变成了“指向那个尴尬位置的位置”!也就是说,我们的pre结点有着落了!接下来,我们还继续讨论头插和中间插两种情况:先二话不说上图 =。=!
1.头插。
可不要以为和上边的图是一样的。其实我只是把里边结点值改成了1、3和5而已(大雾)
于是我们可以看见,原先的情况是,如果我(Node*)判断成功,我就挪到跟我判断的结点的位置,这样就保证了退出循环时temp一定是在需要插入的位置,这就非常尴尬了。然而,经由我们的新的判断条件(*temp)->data < target_data,我们是在远程发动解引用的能力判断大小的,我们temp的类型是Node**,因此最后一定会指向一个next (Node*类型)指针的。因此,最终退出循环的时候,temp一定是在需要插入结点的前边!因此可以完美解决~
2.中间插
按照刚才的分析,temp一定会停留在这里~于是pre指针就有啦!有了pre,还怕没有next吗?所以轻松地,根本不需要第二个一级指针,只需要一个二级指针就可以完美解决啦~~二话不说上图!
最后的next指针是可以经由pre指针得到的!所以,经由这样的操作,我们根本就不需要第二个指针啦!也就是,我们只需要讨论一种情况,就可以完整地把头插和中间插合二为一咯!
当然,口说无凭~还是要列代码的!12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656667struct ListNode{ int data; struct ListNode* next;};struct ListNode *head = NULL;void insert(int data){ struct ListNode *node = (struct ListNode *)malloc(sizeof(struct ListNode)); node->data = data; node->next = NULL; struct ListNode **temp = &head; while(temp && *temp && (*temp)->data < data){ temp = &(*temp)->next; } struct ListNode *next = *temp; *temp = node; (*temp)->next = next;}void delete(int data){ struct ListNode **temp = &head; while(temp && *temp){ if ((*temp)->data == data) { struct ListNode *node = *temp; *temp = node->next; free(node); return; }else if((*temp)->data > data){ //失败 break; } temp = &(*temp)->next; }}void print(){ struct ListNode *temp = head; while(temp){ printf("%d ", temp->data); temp = temp->next; }}int main(int argc, char *argv[]){ insert(3); insert(2); insert(1); insert(5); insert(5); insert(5); delete(5); delete(1); print(); return 0;}