之前的笔记实在是有些简陋,如今要正式地重来一遍咯!
- Observer
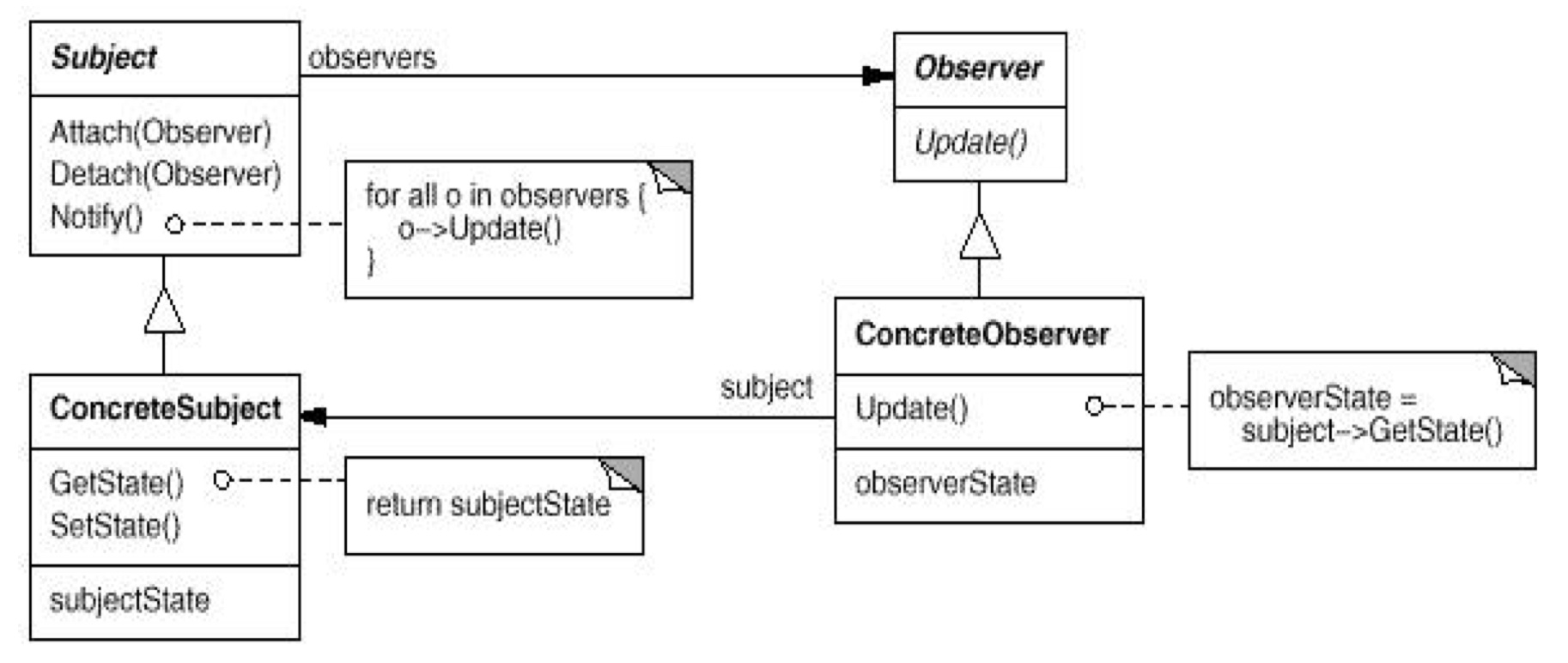 

如 UML 图所见,Subject 和 Object 都是接口,仅仅定义了对于模式实现的方法,而 ConcreteSubject 和 ConcreteObject 才是实现类。
- 对象模型:Subject 中含有一个 Object 的 List,代表它要通知的 Objects。而每一个 Object 中含有一个对自己 Subject 的引用。
pull模式:Subject 中的Notify()方法以及 Object 中的Update()方法才是重点。Subject::Notify()使用轮询的方式来调用它内部每个 Object 的Object::Update()方法。而Object::Update()方法往往又调用 Subject 的Subject::getState()方法来拉取状态。其实这就是 Observer 的pull方法,即由 Observer 自身去拉取的手段。push模式:当然对应地,还有种实现手段是push方法。即 Subject 调用Subject::Notify()开启Object::Update()的时候。传入自身的 State 进去。这样 Object 在实现Object::Update()的时候,就不去要从 Subject 中 pull 来,因为 Subject 已经 push 过去了。但是这样实现,弹性比较小,正常的标准还是pull模式。
- Strategy
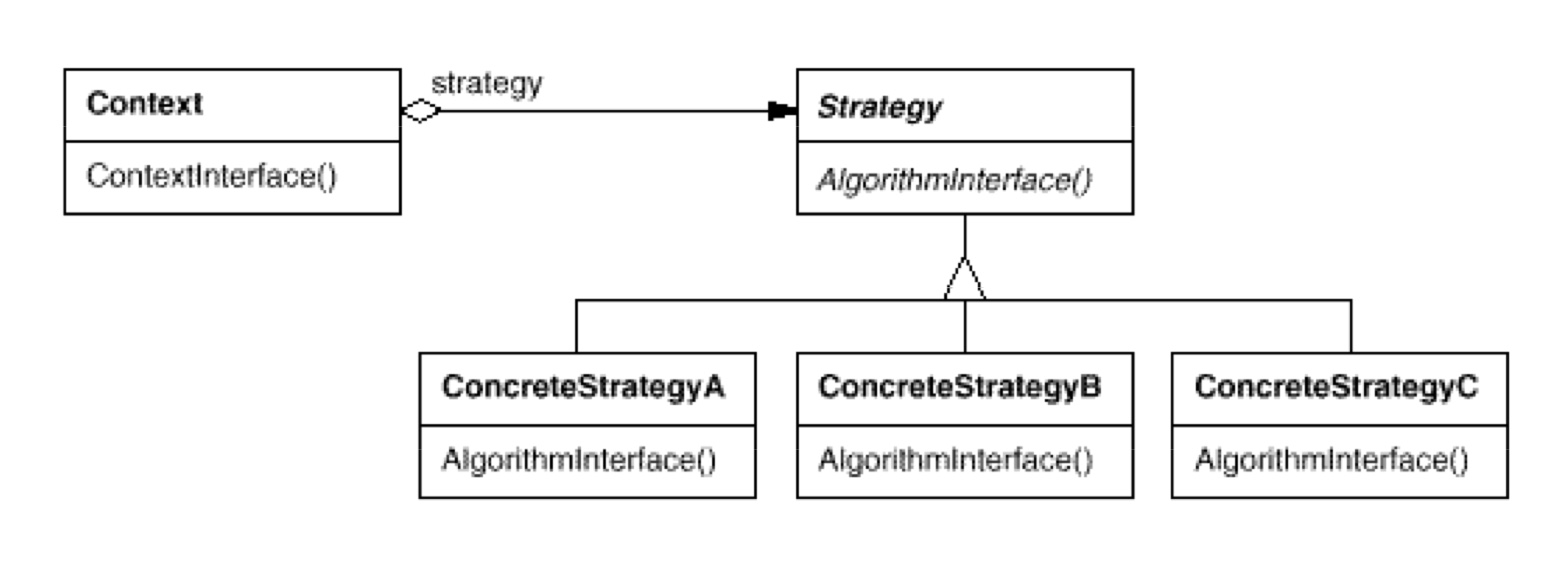 

如 UML 图所见,Strategy 是接口类,仅仅定义了 strategy 接口。而同一层继承体系下,分化出来多个 ConcreteStrategy 类。
- 对象模型:Context 的内部内含一个 Strategy 对象的引用。而 Strategy 是一个接口体系,可以在同一层继承下分化出来多个 SubStrategy。
- 过程:举 awt 的栗子来说:
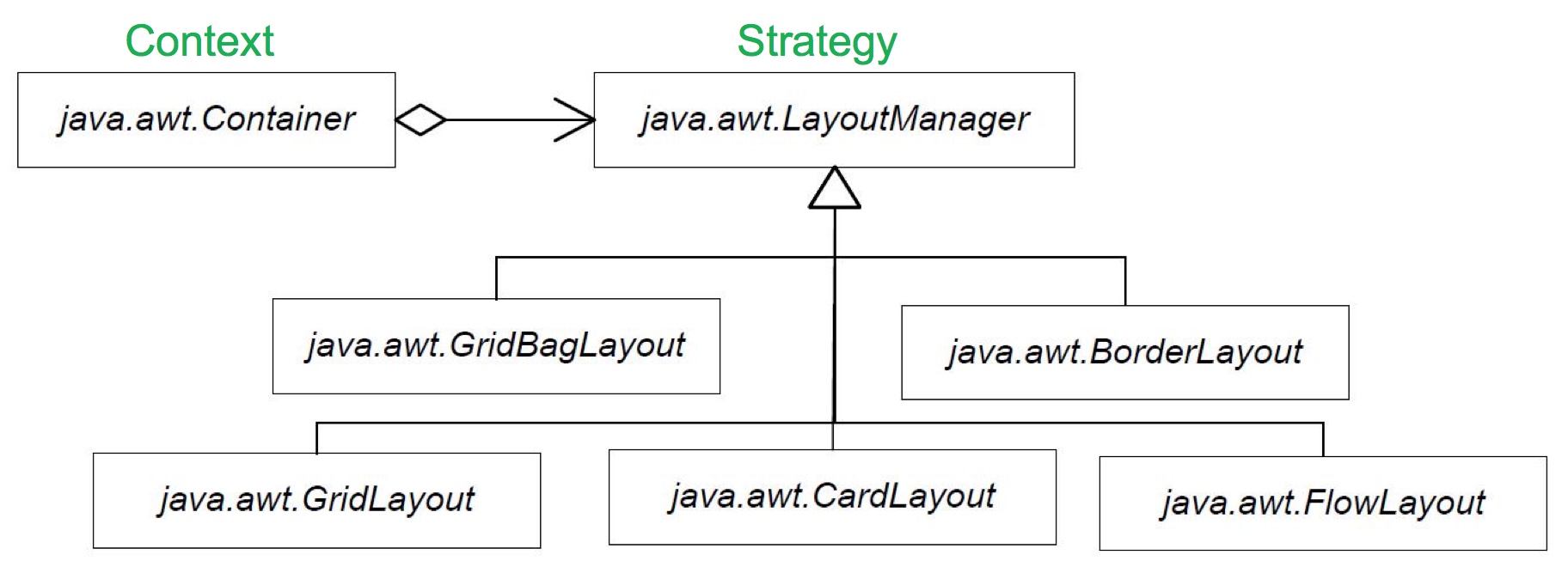 

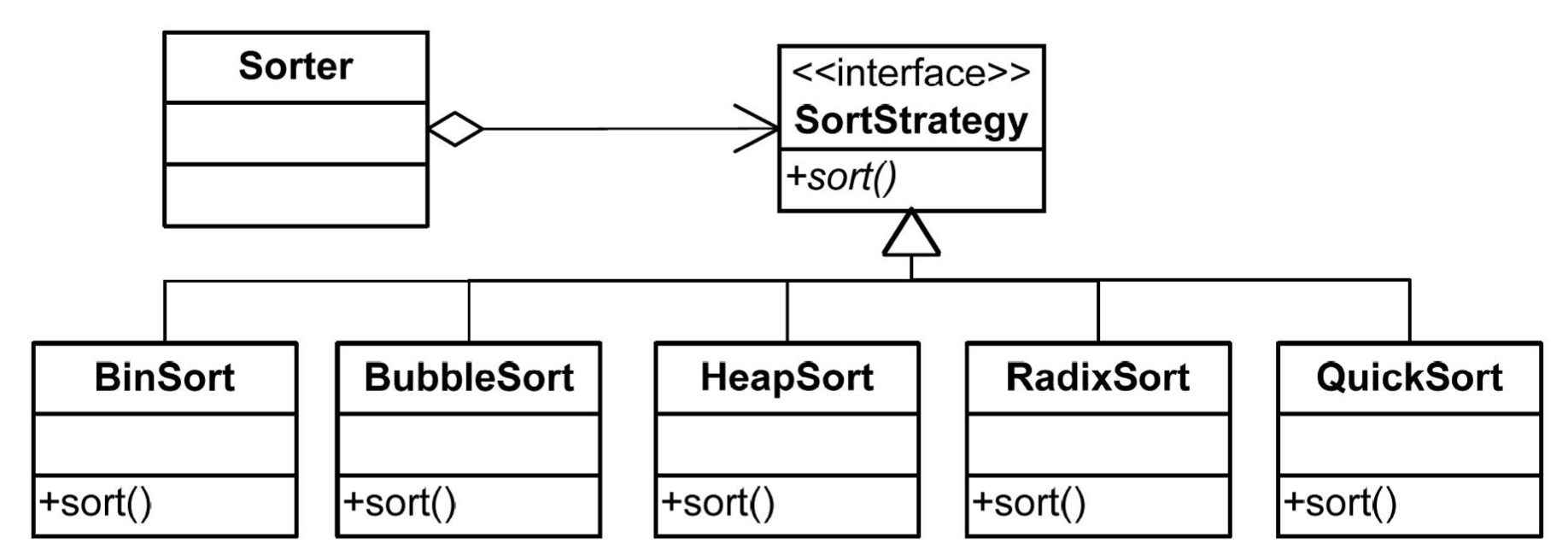
“Java JFrame jframe(…); // JFrame 是 Container 的一个子对象,即 Context jFrame.setLayout(new FlowLayout()); // 添加一个 Strategy 到 Context 中。 jframe.add(new JButton()); // JFrame::add 方法会在内部调用 FlowLayout 的 Strategy 方法,产生一种布局模式。 “ - 更多的栗子:同样的栗子还有:Sorter 内部存放一个 SorterStrategy 的引用,可以赋值为 SorterStrategy 体系下的 SubStrategy,必须 BinarySortStrategy 对象,BubbleSortStrategy 对象,HeapSortStrategy 对象等等。
 - 还有游戏一进去就有的选择困难等级:容易、中等、难、困难、修罗模式这种,也是策略模式的体现!
- Factory
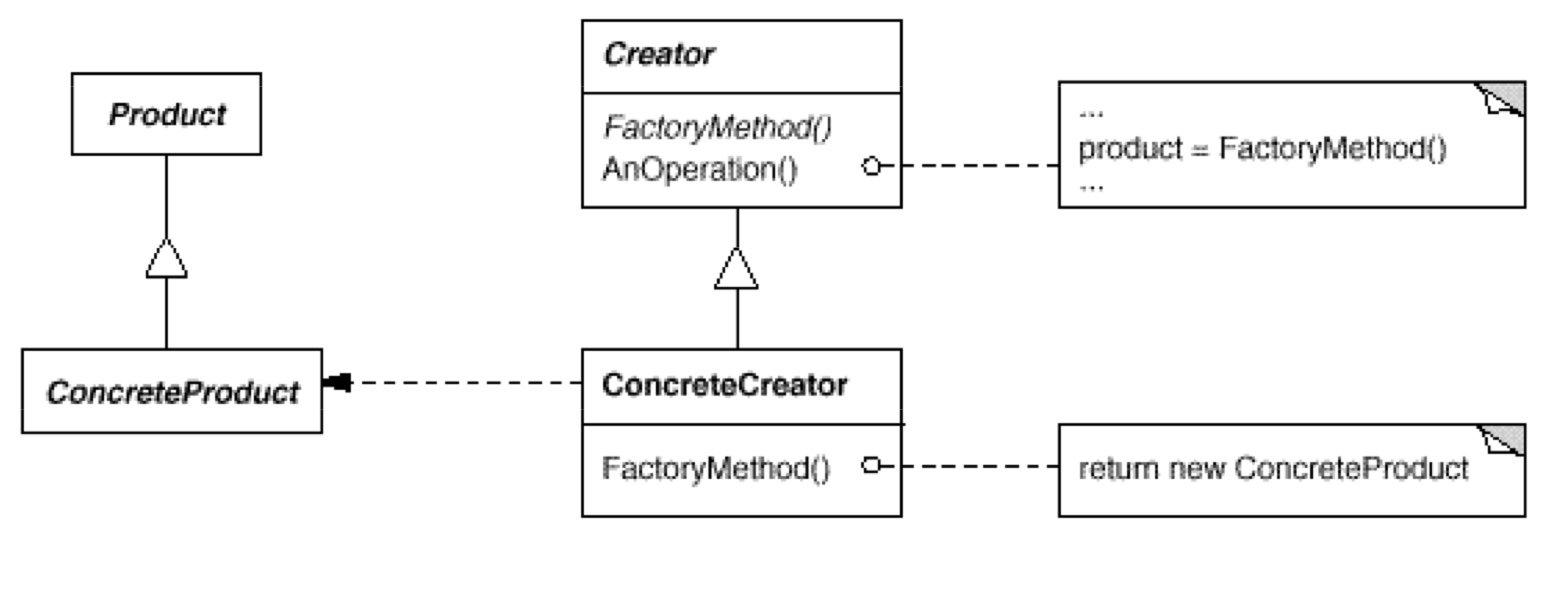 

如 UML 图所见,Product 是一个抽象产品类,下方有继承的 ConcreteProduct 实体的产品类。Creator 是接口工厂,内含多态的Creator::FactoryMethod方法,返回一个集成体系下的顶层抽象产品类Product。ConcreteCreator 是实体工厂,用于生产 ConcreteProduct。
- 对象模型:Creator 工厂内部没有任何成员变量,只有工厂方法。但是 Creator 工厂内部的方法可以全是 static 的。这就是一种变种,叫做静态工厂。好处在于,不用创建工厂的实体对象了~
- 变种1:简单的工厂方法:不需要写抽象的 Creator,因为体系比较简单,直接上来就是一个简单的实体+静态工厂。
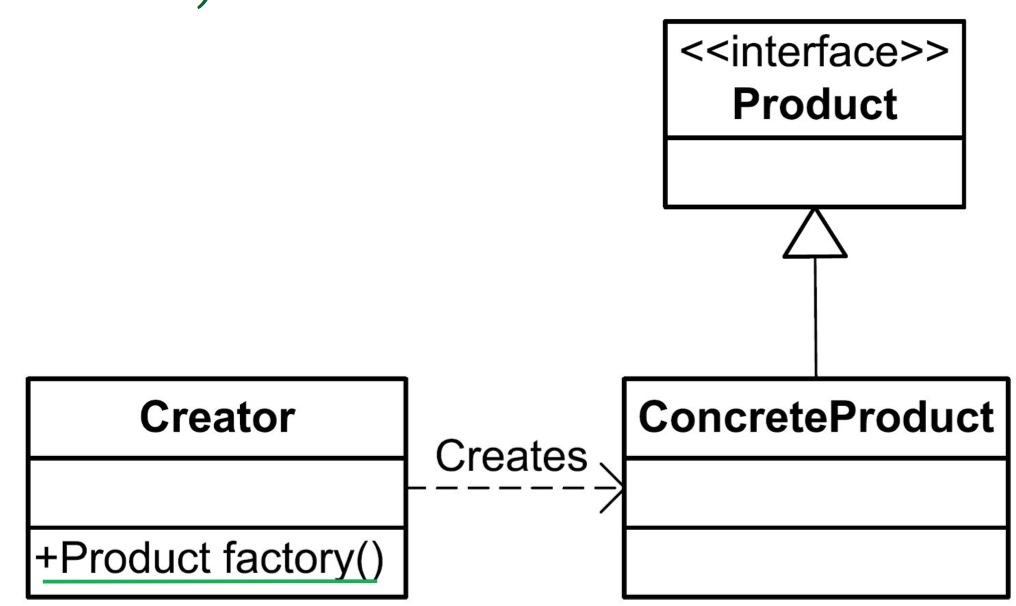 
 - 变种2:对于生产同一个继承体系的多种产品,可以在工厂中只写一个方法,内部使用
if…elif…else的手段,最后产生的对象挂接到高层产品接口的句柄上返回。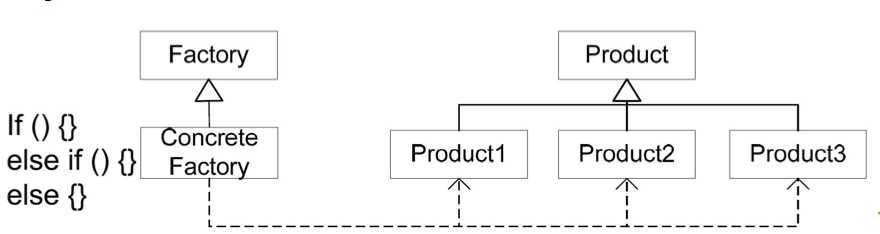 

如图,此 Concrete Factory 的produce()方法签名返回高层的 Product。 - 变种3:Product 接口自己就是一个工厂,可以使用多态(子Product 中分别实现)产生继承体系下的多种类型的 ConcreteProduct。当然,这个多态工厂方法必然返回
Product*的句柄就是,而且可以使用static静态方法。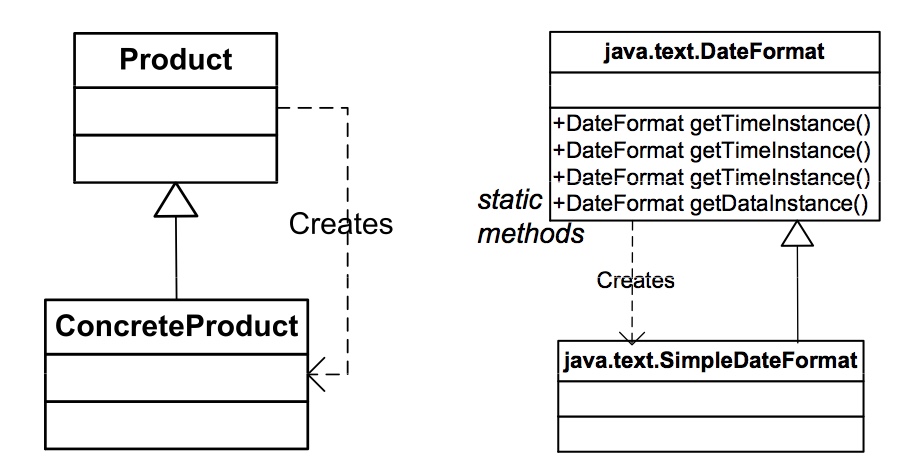 
 - 变种4:ConcreteProduct 本身是一个工厂,可以产生自己。(我们只有一种产品)
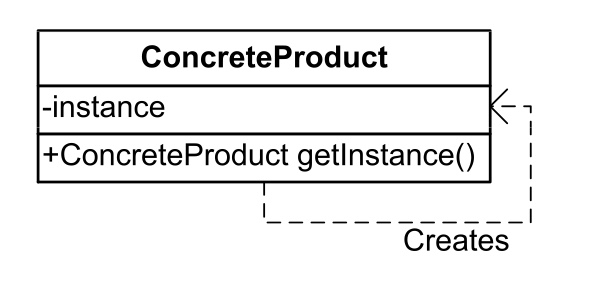 
 - 用途:Java 框架中的依赖注入(IoC中) 等等。
- Abstract Factory
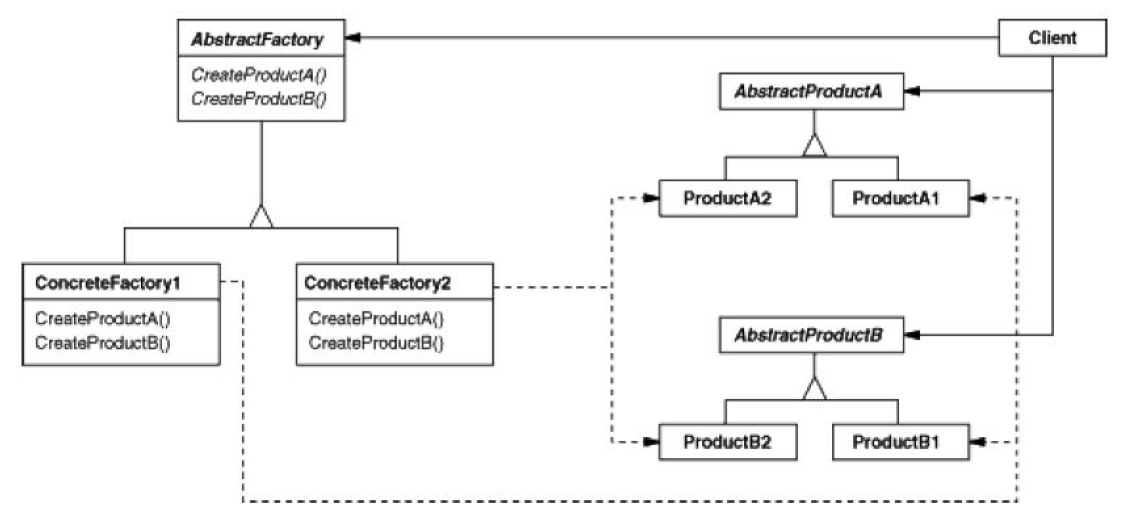 

和 Factory 的不同之处仅仅在于,
- Abstract Factory 是把工厂自身当做产品的。即,生产工厂的工厂。
- Abstract Factory 由于有上边的这种性质,因此它不再局限于只能像 Factory 一样仅仅能够生产一个体系中的 Product。通过生产出不同类别的工厂,它能够自扩展而生产别的体系的 Product。我们从 UML 图即可看出。
- 缺点:支持新种类的 Product 变得很麻烦了。
- Decorator
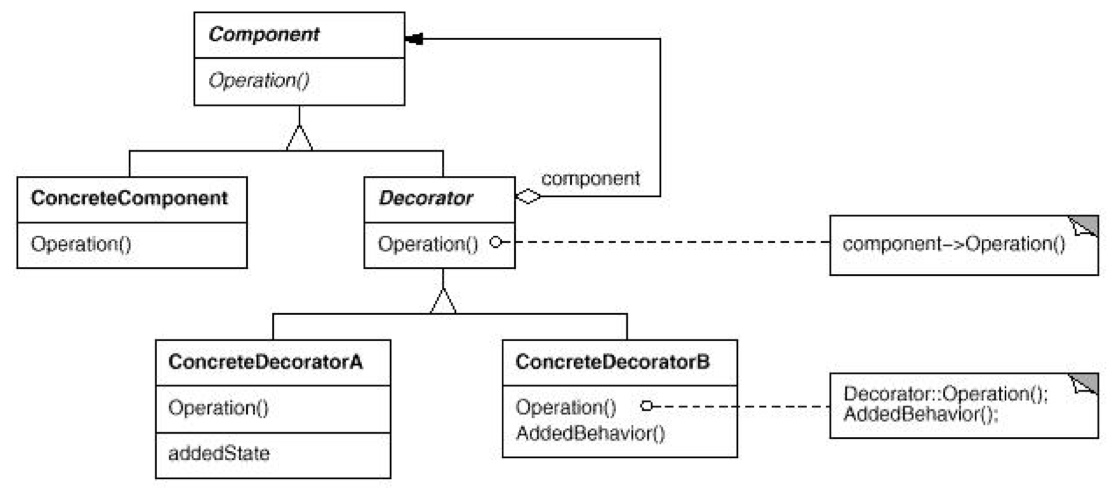 

如 UML 图可见,最高层是一个抽象类 Component。它下方一定有一个直属的子类 ConcreteComponent,要不 Decorator 无法使用了。因为 Decorator 虽然也继承 Component,但是它的内部也有一个 Component 的句柄引用!那个句柄引用的正体显而易见就是那个直属的 ConcreteComponent。因为装饰者模式的策略就是:在同一继承体系中,使用已经实现好的子类,在新的子类中扩展它的功能,变成新的功能。
- 对象模型:ConcreteComponent 成员变量不能有同类的 Component 句柄,但是 Decorator 的内部必须有一个同类的 Component 句柄!因为 Decorator 要对 ConcreteComponent 的功能进行扩展,从而衍生出自己的新功能,而不用完全从头来写。Decorator 的构造函数要传递一个被扩展的同体系的对象,UML 图中即是 ConcreteComponent。
- 经典用途:Java 的 IO 系统。比如 BufferedInputStream 啥的都是继承自上层的 InputStream,但是自己构造的时候又要接收一个 InputStream 对象。
 
 - 这也就给出了:为什么不在类上用继承进行扩展呢 这个问题的真正答案。很简单,因为装饰者模式比继承要灵活,弹性更大。像我们的 BufferedInputStream,既可以接收别的 FileInputStream,也可以满足比如来自 Socket 的 socket.getInputStream() 的接收这样的场景。所以,如果上层有其他的 InputStream 体系的实现,BufferedInputStream 这个装饰者可以对他们进行统一扩展,而不再仅仅局限于继承的仅仅扩展一个InputStream。这样弹性会变得非常巨大~
- Singleton
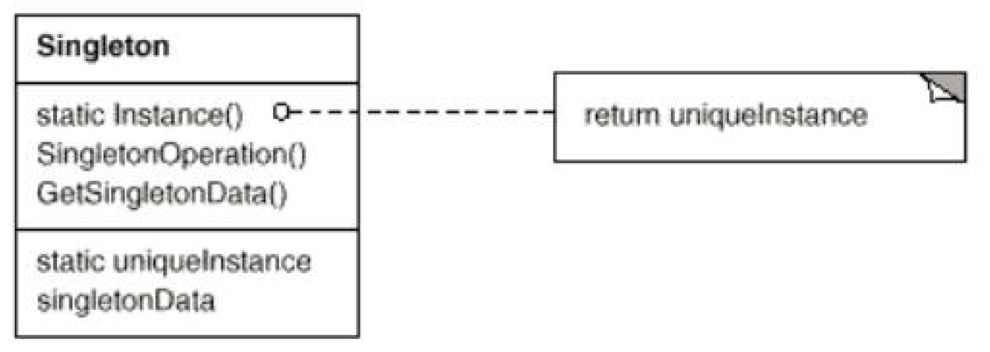 

这个实在是基础中的基础,不讲了。但是在多线程之下,Java 中 Singleton 模式也是有很多大坑的,尤其是 LazyEvaluation。
单例模式的博客
不过要换成 C++,就连 Eager Singleton 也有大坑!!!
一开始,我认为只有这样,用shared_ptr智能指针才行:
“`cpp
// 错误的 Singleton 范例!!
class Singleton{
private:
static shared_ptr singleton;
Singleton() {}
public:
static shared_ptr getSingleton() {
return singleton;
}
};
shared_ptr Singleton::singleton = shared_ptr(new Singleton); // 用原生指针 new 一个 static 变量,最后会造成内存无法释放而泄漏。
“上边的想法确实在我自己看来是还中规中矩的……不过这两天正好读完了 Scott Meyers 的 Effective C++……其中的第四条款指出,static 这种全局变量,虽然会在使用时初始化,但是和 Java 也有本质的不同。Java 的话,在虚拟机 JVM 进行类加载的时候,会有一个“类的初始化”期,这期间会直接初始化所有 static 变量和 static 块。因此,Eager Singleton 在 Java 中可谓是天然适配,上来就默认多线程友好;但是 C++ 不一样……确实在调用之前,static 也会初始化;但是 C++ 标准并没有规定 **多个编译单元中 static 的初始化顺序**!!也就是,在多个模块中,non-local static 变量的初始化顺序是未知的!具体原因请直接看 Meyers 的 Effective C++ Item 04。因此,Meyers 指出,在 C++ 想要 Singleton 安全,必须把 non-local static 变成一个 local static,其实表现形式上,变成了一个**工厂函数**!更改后的程序见下:
“cpp
// 正确的 Eager Singleton,而且不再使用恶心的 static new!
class Singleton{
private:
Singleton();
Singleton(const Singleton &);
Singleton& operator= (const Singleton &);
~Singleton();
public:
static Singleton& getSingleton() {
static Singleton singleton;
return singleton;
}
};// 注意一定要注销掉 copy constructor 以及 constructor 还有 assignment operator!!要不,最后会发生可以拷贝的愚蠢现象……比如 Singleton s = getSingleton(),因为调用的是拷贝构造函数……所以必须 private 化。因为 C++ 可以分配在栈上,因此和 Java 全是堆引用不同~
“`
参考了一个博客:ZKT的笔记本,在我迷惑的时候它帮助了我。当然,虽然还没有看,但是《Modern C++ Design》中用 TMP 来 hack 各种设计模式也非常令人憧憬~
至此单例模式完成……没想到竟然引申出了这么多东西……颇有收获~
多例模式的话,就 new 一个 ArrayList 就可以。布局和 FlyWeight 模式有点像,不过那个的内部是一个 HashMap。
- Command
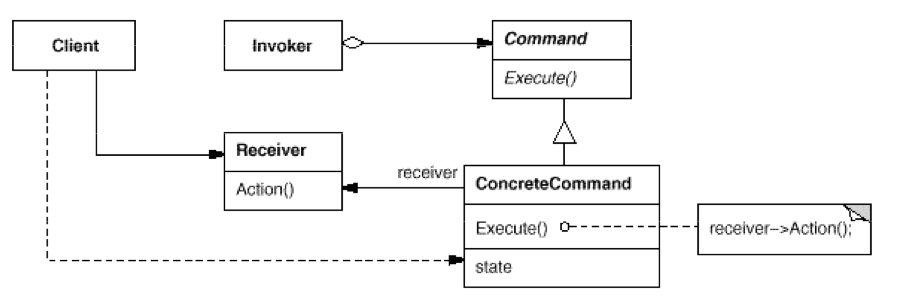 

如 UML 图可见,Client 客户端先要创建一个具有各种动作的 Receiver,虽然 GOF 只画了一个 Action()。其实内部可以有 ActionEat(),ActionDrink(),ActionPlay() 等。而 Command 的分化也可以有 ConcreteEatCommand,ConcreteDrinkCommand 以及 ConcretePlayCommand 等分化类,用于持久化各种 Action 命令。
- 对象模型:Command 是一个抽象类,内部有一个引用的成员 Receiver 和一个 Execute 方法,Execute 旨在调用
多个 receiver.action(),从而把receiver.action()延后化。即,把receiver.action()这个瞬间的调用给封装成了一个 Command 对象藉以持久化,达到推迟receiver.action()执行的最终目的。ConcreteCommand 是一个实现类。Invoker 其实就是一个 List 的封装,把所有的动作全都使用 Command 延时化,然后集结到一块,通过Invoker::invoke()来进行一块执行所有 Command 达到最终的延时操作 actions 的目的,即 MacroCommand。 - 变种:Undo and Redo:
可以通过和Command::Execute()方法并列编写一个Command::Undo()方法。比如Command::Execute() { receiver.turnOnLightAction(); },那么Command::Undo() { receiver.turnOffLightAction(); }就可以被如此实现。 - 用途:执行一系列延时操作;打 Log。
- Adapter
- 类配接器:
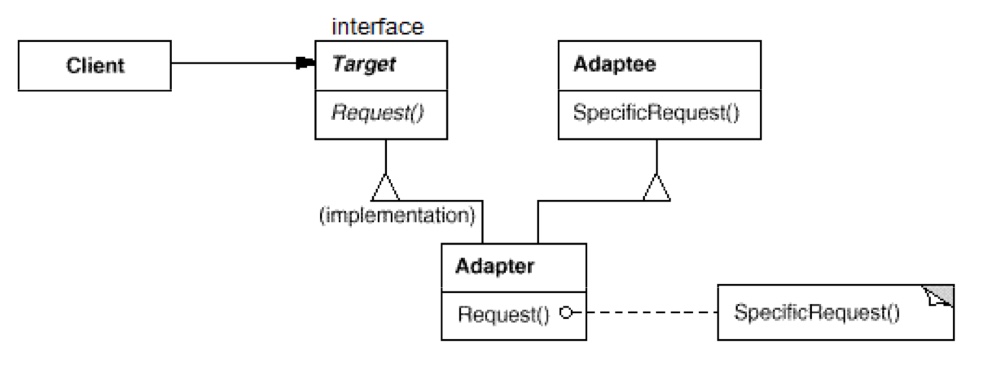 

如 UML 图可见,Adaptee 是一个我们原本拥有的、但是和正规接口不符的要被配接的对象。我们使用多继承,继承自 Target 和 Adaptee,产生一个新的 Adapter,实现 Target 的正规接口,内部只要调用Adaptee::SpecificRequest()即可。其实十分简单。 - 对象配接器:
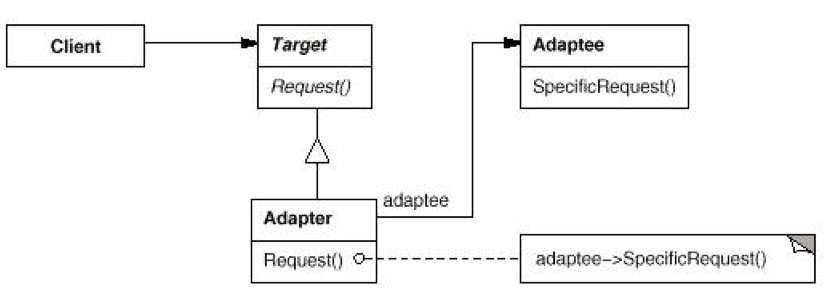 

如 UML 图可见,Adapter 使用了聚合的方式代替了继承的方式。STL 中的容器配接器 stack 也是这么实现的。同样,在Adapter::Request()中直接调用Adaptee::SpecificRequest()即可。
- Facade
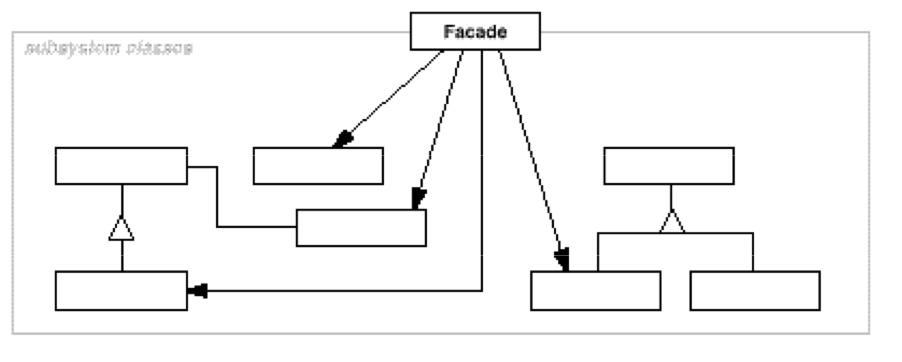 

外观模式更像一种软件的架构模式,因此没有 UML 图。外观模式其实在我的理解类似于模块化,通过模块化的方式来定制多种模块接口,来呈现出美观的外观。子系统内部的任何变化不会影响到 Facade 接口的变化! - Template Method
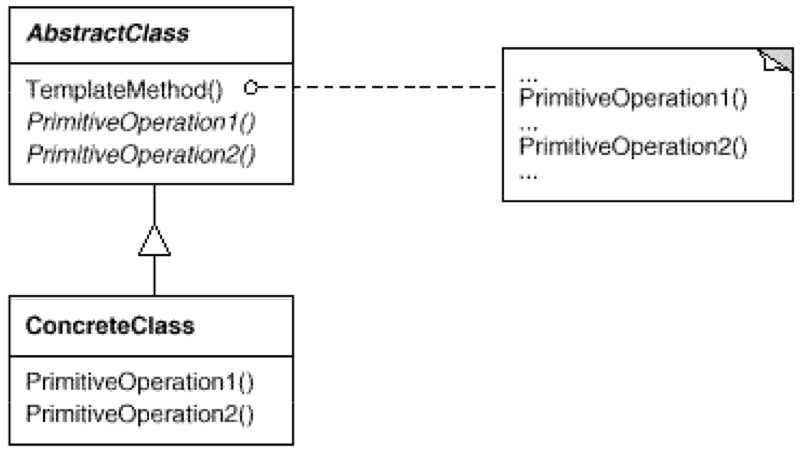 

如 UML 图可见,我们在一个抽象类 AbstractClass 中写下TemplateMethod()方法,内部指定代码逻辑的实现,分别按顺序调用PrimitiveOperation1和PrimitiveOperation2这两个方法。然后后二者使用多态,可以在子类中自由变更。但是TemplateMethod()方法永远保持不变。
- 应用:
HttpServlet中的doGet(),doPost()等多种方法。注意它们的命名用do-前缀开头。而且在 Servlet 的大逻辑的实现中,这些do-方法是按照 TemplateMethod 模式,按照一定的逻辑进行调用的。我们所更改的只是doGet()和doPost()的内部逻辑,但是外部的大框架逻辑并没有改变!
- Iterator
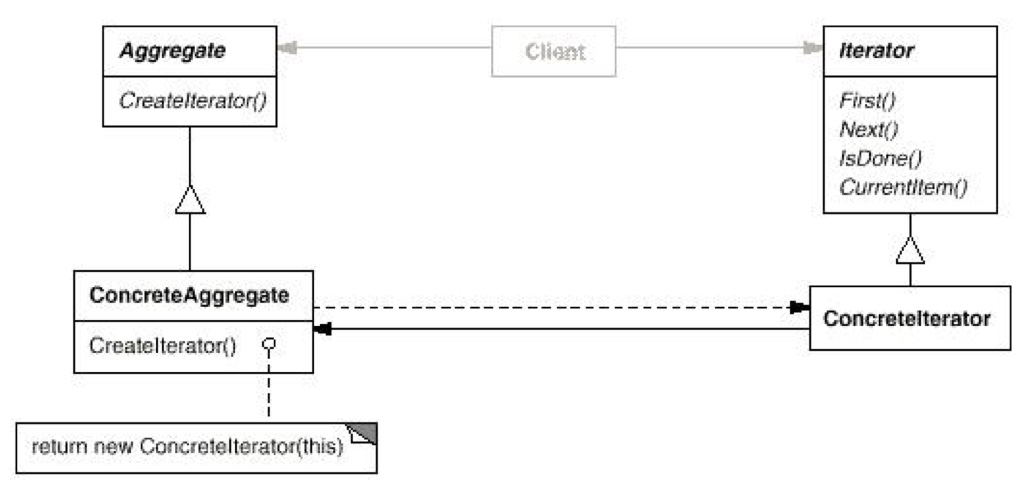 

迭代器分有内部、外部、静态、动态多种。不过大多数都是内部的“标准”迭代器。C++ STL 完全基于迭代器,让容器的遍历和容器自身完全分离开来,而且可以让外部无法知道容器内部的细节。几乎是最常用的设计模式之一,不过多解释了。 - Compose
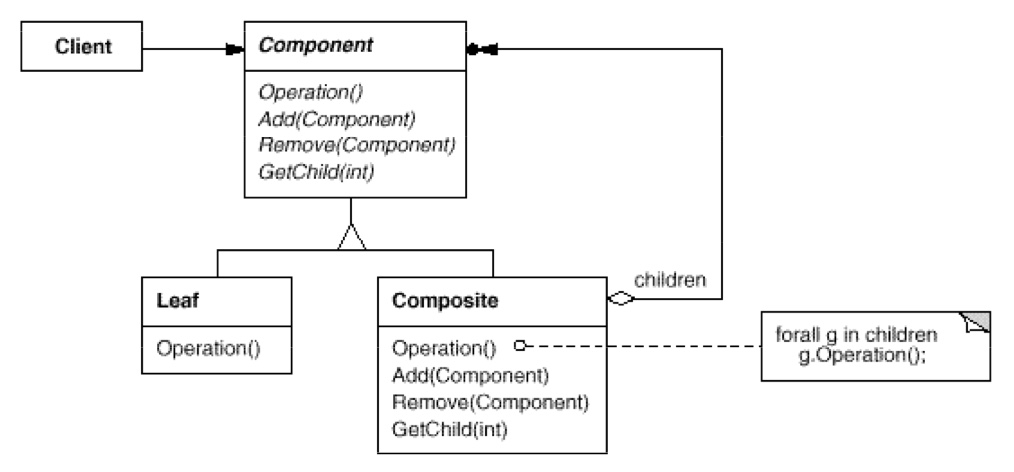 

组合模式最常见的就是树形结构。其实它的结构和 Decorator 有些像,但是作用是天壤之别。
- 例子:这个模式用例子来解释是最好的,就是文件系统。抽象的文件类就是 Component 这个抽象组件节点类,而 File 就是 Leaf,Folder 就是 Composite:它的内部含有一个
List,即 Folder 中可以含有 File,更可以含有其他 Folder。那么这个 UML 图就非常明了了。注意 Compose 模式的重点是树形结构就好。
- State
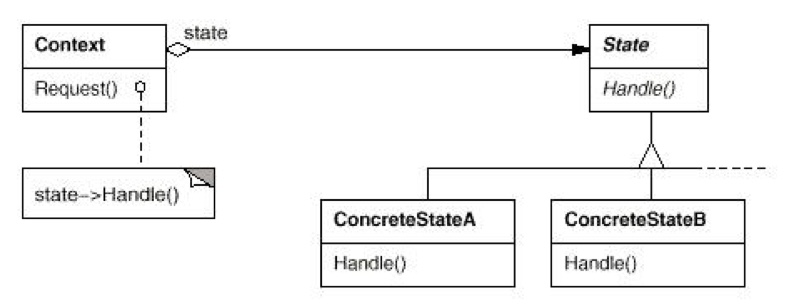 

状态模式和策略模式比较像。只不过,Strategy 模式中,一个 state 对应多个 Strategy;而 State 模式中,多个 State 都有自己的不同的行为。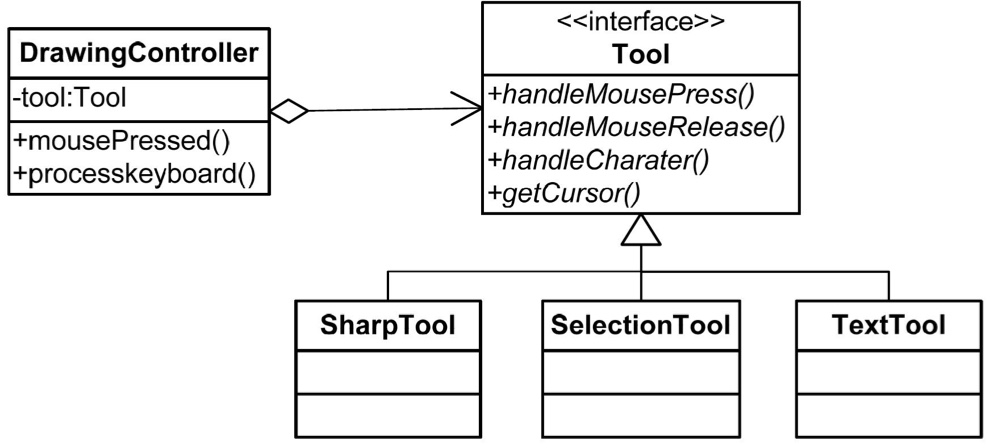 

如上图,每个 Tool 子类都重写了 Tool 接口的四个方法。其实这和 Strategy 真的差不多。只不过 State 模式不同对象代表不同的状态,而 Strategy 总体是在一个大状态之下,而选择了不同的 Strategy 而已。 - Proxy
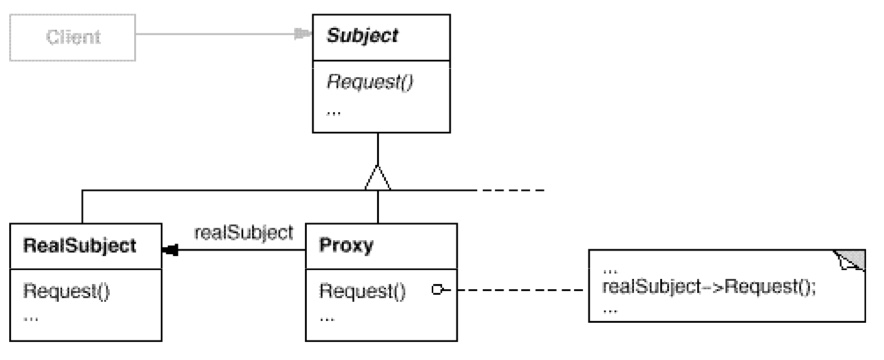 

由此 UML 图可见,Proxy 和 RealSubject 都继承自 Subject 这个抽象类。都有 Request 方法。而 Proxy 的内部具有一个 RealSubject 的句柄,而Proxy::Request()的内部则是调用了realSubject->Request()。即,Proxy 代理 RealSubject 来进行 RealSubject 的职务。
- 用途:比如网络的代理软件、操作系统的软链接、智能指针等等。
- FlyWeight
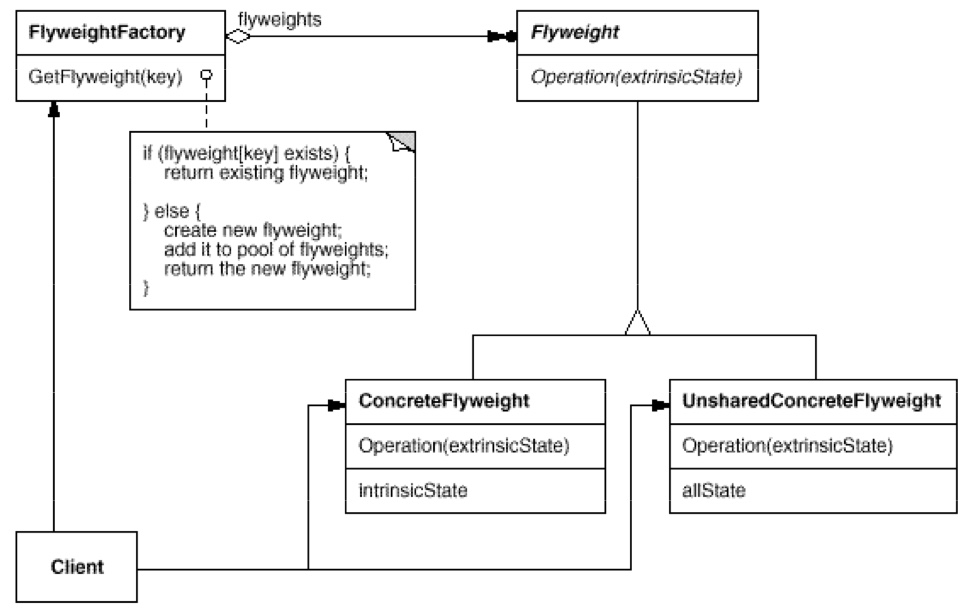 

FlyWeight 模式一般都自带一个工厂,工厂一般都可以是 Singleton Factory,内部一般存放一个 HashMap。其实在个人看来,C++ 的map就非常符合 FlyWeight 的观念,尤其是它重载的operator []。FlyWeight 模式在向内调用FlyWeightFactory::GetKey(Key key)方法的时候,如果 key 在内部的 HashMap 中已经存放过,那么就直接取出来它的句柄,把句柄返回去。如果没有存放过,那么就把此 Key 的句柄放到 HashMap 中存放。 - Builder
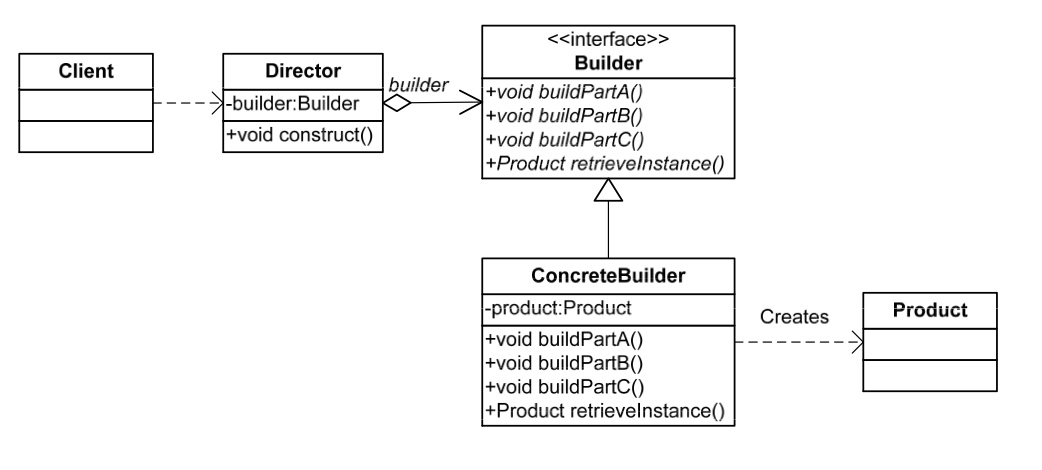 

- 对象模型:Builder 模式中,有一个 Director 占据主导地位。
Director::construct()是拼装组件的入口函数。Director 内部有一个 Builder 的 reference。Director 通过调用builder.buildPartA, builder.buildPartB, builder.buildPartC在 builder 内部产生多个组件。而这个Builder::retrieveInstance内部会由 Builder 内部所维护的成员变量partA, partB, partC来进行 construct 出一个 Product。注意:在 Builder 内部维护的成员变量仅仅是成员组件 partA/B/C,只有在 retrieveInstance 的时候才会真的生成一个 Product。 - 如果把 Director 省略掉,那么就和 Factory 差不多了。不过 construct 函数要被从 Director 中迁移到 Builder 中,并且必须在 retrieveInstance 之前调用。
- Chain of Responsiblity
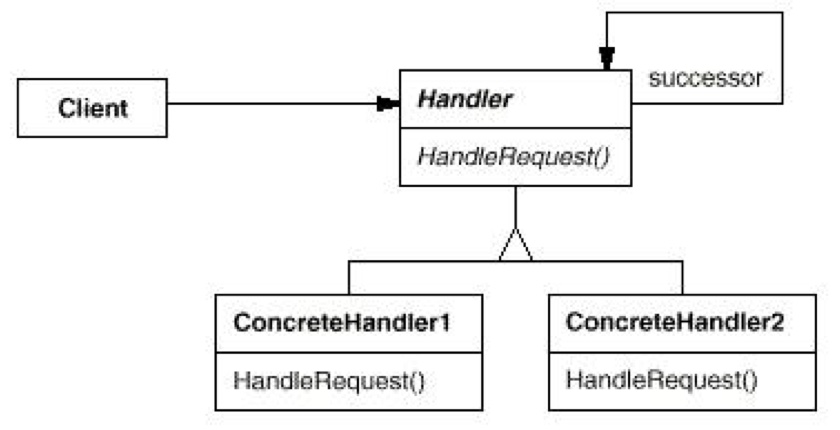 

- 对象模型:Handler 类本质上是一个单向链表,next 即是自己。内部含有
HandleRequest()方法,用来处理这个 Handler。当然,Handler 可以派生出多种类型,然后共同组成一个链。HandleRequest()是会对此节点及之后的所有节点做处理的。所以只要在第一个节点处调用HandleRequest()即可。
- Mediator
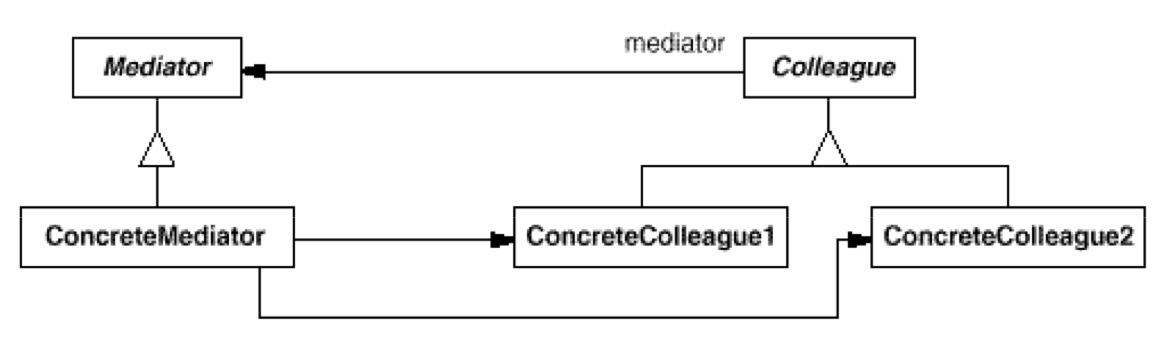 

中介者模式主要是为了避免过度耦合的现象发生的。比如同事,在软件工程的原理中,如果没有中介人,那么同事之间要两两互相认识,太麻烦了。因此中介人即是起到保存所有同事的作用;而且每个同事之中还要保存中介人的引用。
- 对象模型:如上边所说,每个 College 之中要保存 Mediator;而 Mediator 中保存了所有的 Colledges。
- Bridge
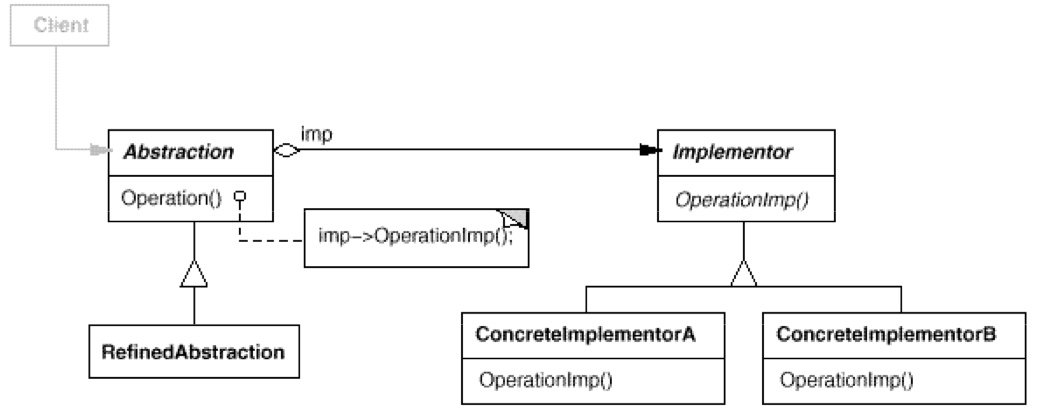 

Wikipedia:如“圆形”、“三角形”归于抽象的“形状”之下,而“画圆”、“画三角”归于实现行为的“画图”类之下,然后由“形状”调用“画图”。
即:将类的功能层次结构和实现层次结构分离。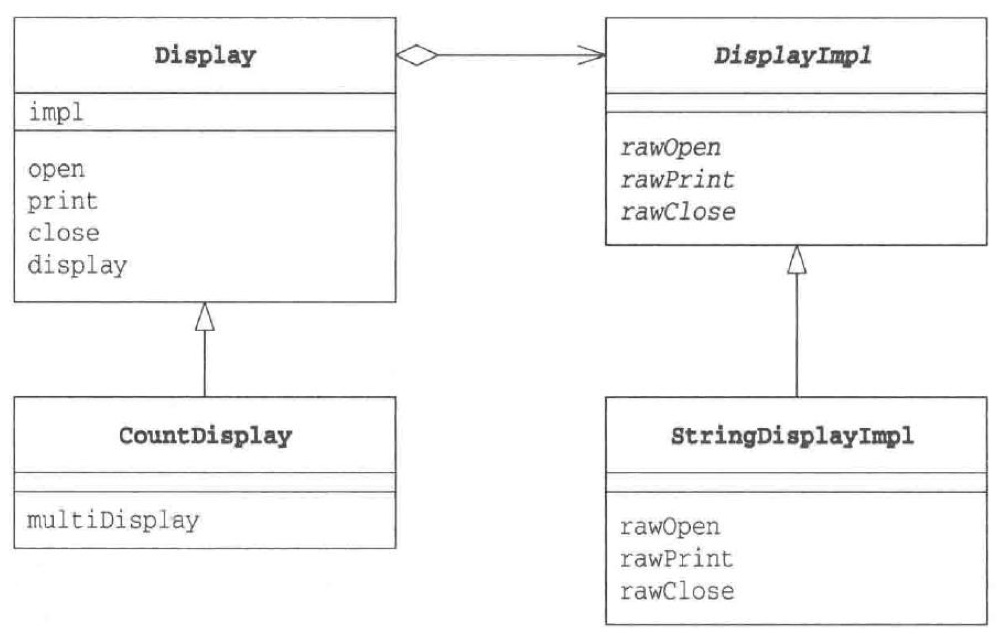 

如图,各个方法的实现全部放在 DisplayImpl 中去,而 Display 和 CountDisplay 中拥有 DisplayImpl 实现方法对象,可以调用 Display 的各个实现方法组合成不同的实现。比如打印一次或者五次。 - Prototype
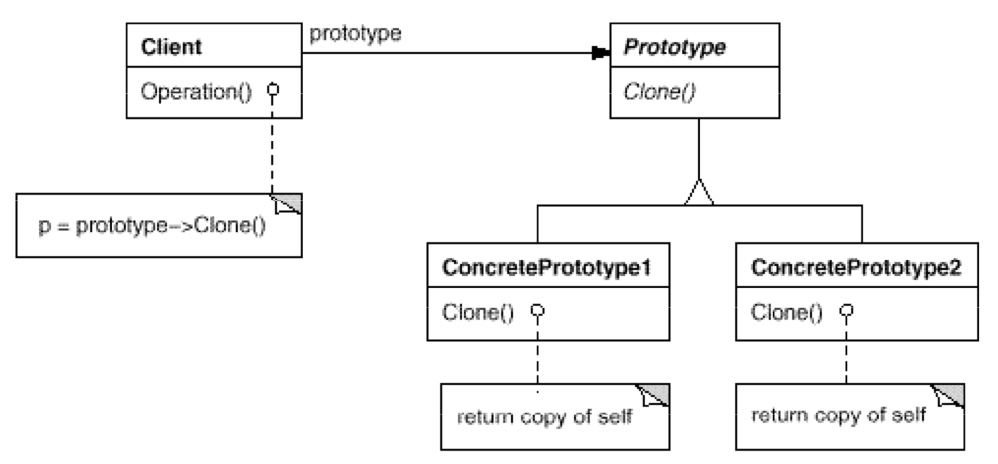 

其实就是 Java 的 Cloneable 接口。根据深拷贝而形成的 Clone 方法。其实和 C++ 的 copy constructor 差不多。但是实现中要防止循环引用的深拷贝。 - Memento
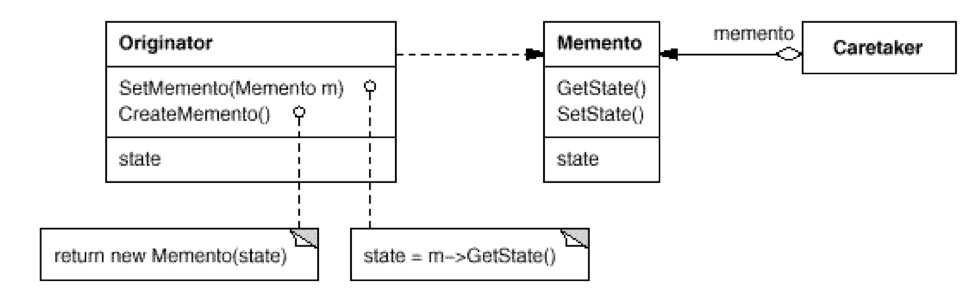 

- 对象模型:备忘录模式具有 Memento、Originator 以及 Caretaker 三个组件。Memento 在这里是一个 bean,内部具有一个 state 成员,标志着状态。而
Originator::SetMemento()接收一个 Memento,拆包并且把 state 设置为自己的 state。而Originator::CreateMemento()会再把 state 封包成一个 Memento 返回出去。而 Caretaker 即是一个 List,存放多个 Memento。 - 注意:这三者职责非常明确。Memento 只是一个包装类,只有包装的作用;Originator 原发器具有读取备忘录 的作用;而 Caretaker 只有保存备忘录以及转发的作用,并没有查看备忘录的权限。
- 注意2:概念:宽接口 —— 正常的功能齐全的接口 窄接口 —— 啥功能都没有的接口。对 Originator 会提供 Memento 的宽接口;而对于其他的类则提供 Memento 的窄接口 —— MementoIF。而其实 MementoIF 是定义在全局的,而 Originator 中才定义了 Memento 继承于 MementoIF。也就是,只有 Originator 才能解开 MementoIF 的秘密~
备忘录模式详解 - 对所有对象都提供正常的 Memento 的,叫做白箱 Memento 模式;而只对于 Originator 才提供正常宽接口 Memento 的,对于其他对象统统提供 MementoIF 的,叫做黑箱 Memento 模式。这种模式对于封装性非常有用!!
- Visitor
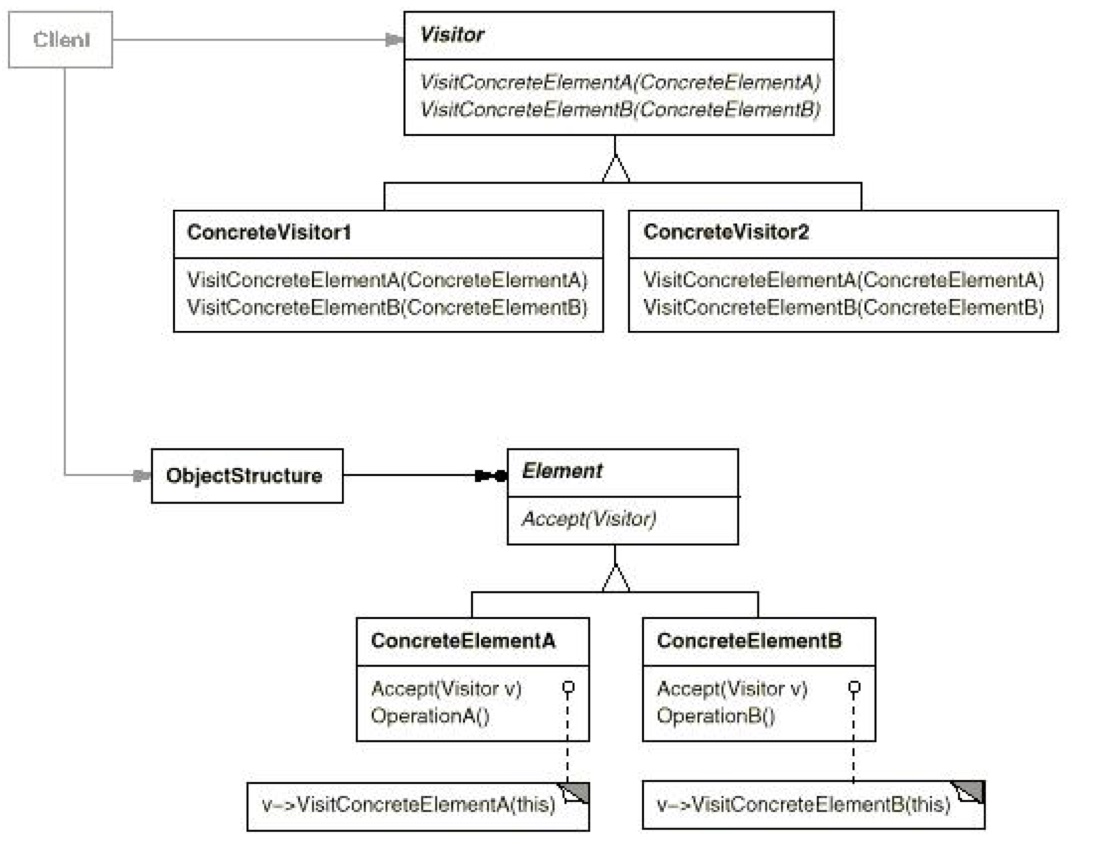 

Visitor 模式非常有用,也很复杂。写 parser 必备。各种 AST 子节点都需要 visitor 模式来进行对子节点的一一访问,配上模板的类型推导可食用。具体代码见我的上一篇博客。 - Interpreter
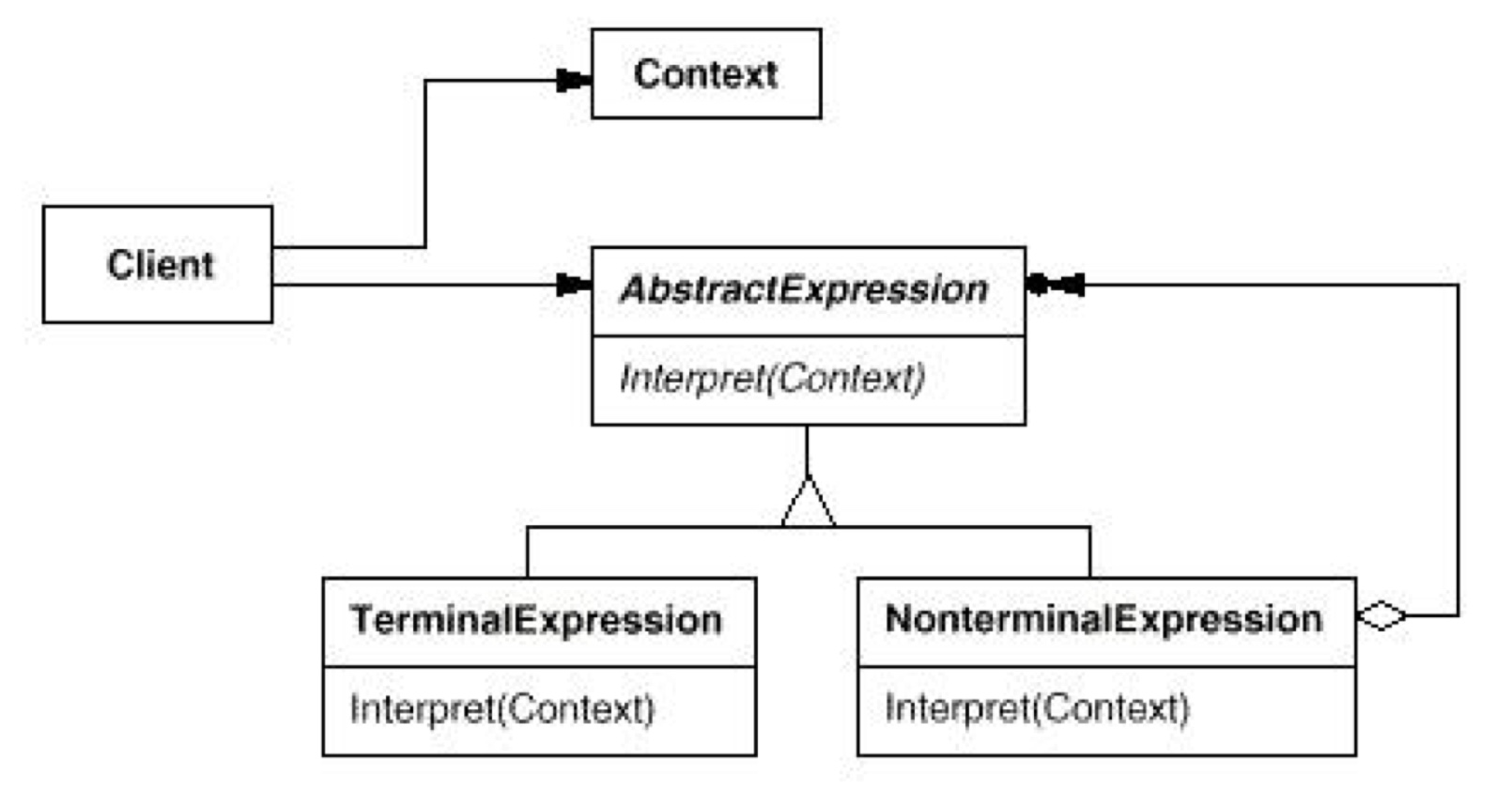 

解释器模式就略了。其实就是写一个简单的 parser。非终结符和终结符,就是类似 BNF 范式。




